spark |
您所在的位置:网站首页 › spark groupbykey 超内存 › spark |
spark
|
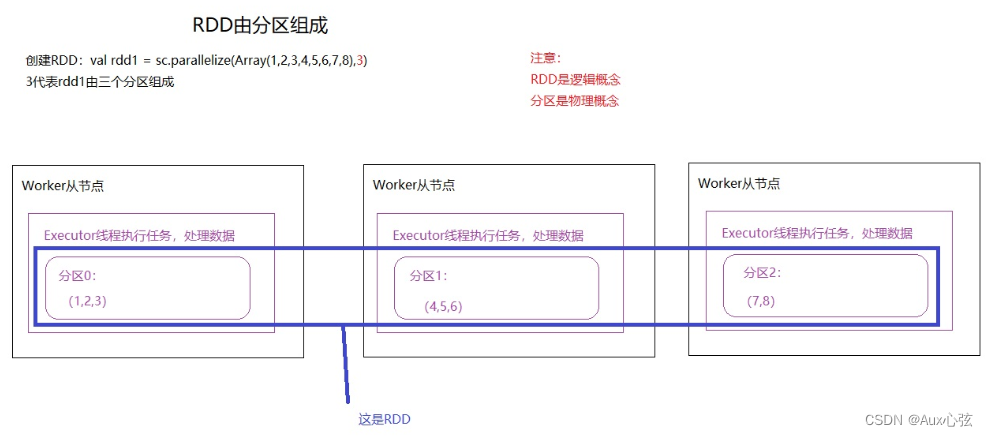
N.1 RDD基础 N.1.1 RDD介绍 1)什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。 可以认为是RDD就是多个数据块(或分区)构成。 2)RDD特性 (1)是一组分区(list of partitions): (2)理解:RDD是由分区组成,每个分区运行在不同的Worker上,通过这种方式来实现分布式计算,RDD是逻辑概念,分区是物理概念。 (3)即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目 ————————————————————————
———————————————————————— (4)每个分区的都有计算函数(function for computing each split) 在RDD中,有一系列函数,用于"处理计算"每个分区中的数据,这里把"函数"叫算子。 Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果 (5)RDD之间的依赖关系(list of dependencies on other RDDs): RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。 (6)自定义分区规则来创建RDD 创建RDD时,可以指定分区,也可以自定义分区规则,类似于MapReduce的分区 (7)优先选择离文件位置近的节点计算 现在基本使用的是移动计算。 移动计算就是把计算任务下发到数据所在的节点进行处理。 移动数据就是将数据移动到计算任务的节点,这样将损耗大量网络开销,导致流量激增,处理效率慢。 3)RDD的创建方式 (1)通过外部的数据文件创建,如HDFS val rdd1 = sc.textFile(“hdfs://192.168.88.111:9000/data/data.txt”) (2)通过sc.parallelize进行创建 val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8), [分区个数] ) //默认分区数为2 ————————————————————————
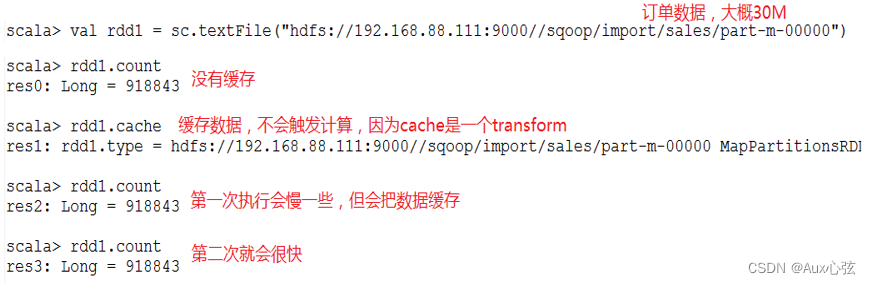
———————————————————————— N.1.2 RDD的缓存机制 1)RDD通过persist(底层方法)方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面快速重用。 ————————————————————————
————————————————————————
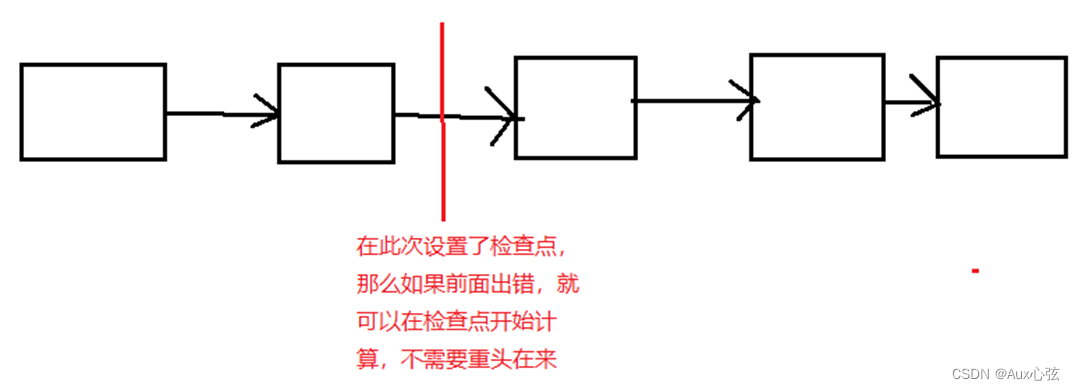
———————————————————————— 2)缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。 N.2 RDD的Lineage机制和Checkpoint 1)检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。 2)设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS。一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据。 ————————————————————————
———————————————————————— 3)本地目录 注意:这种模式,需要将spark-shell运行在本地模式上; 是先设置检查 在远行; ————————————————————————
———————————————————————— 4)HDFS的目录 注意:这种模式,需要将spark-shell运行在集群模式上 ————————————————————————
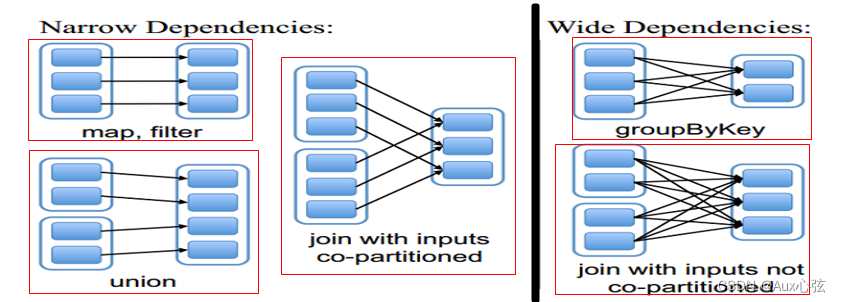
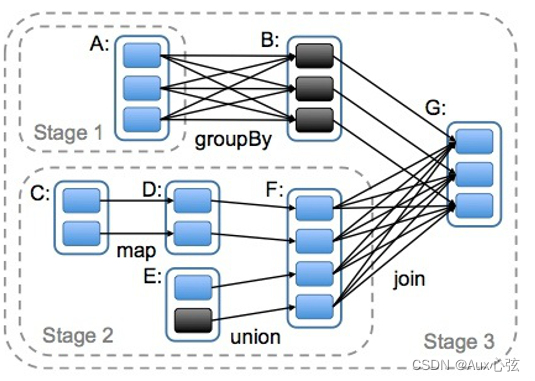
———————————————————————— 5)Checkpoint和持久化机制lineage的区别? (1)最主要的区别在于持久化只是将数据保存在BlockManager中,但是RDD的lineage(⾎缘关系,依赖关系)是不变的。而checkpoint执⾏完之后,rdd已经没有之前所谓的依赖rdd了,⽽只有⼀个强⾏为其设置的checkpointRDD,checkpoint之后rdd的lineage就改变了。 (2)持久化的数据丢失的可能性更⼤,因为节点的故障会导致磁盘、内存的数据丢失。但是checkpoint的数据通常是保存在⾼可⽤的⽂件系统中,⽐如HDFS中,所以数据丢失可能性⽐较低。 6)Spark支持故障恢复的方式? (1)⼀种是通过⾎缘关系lineage,当发⽣故障的时候通过⾎缘关系,再执⾏⼀遍来⼀层⼀层恢复数据; (2)另⼀种⽅式是通过checkpoint()机制,将数据存储到持久化存储中来恢复数据。 N.3 DAG有向无环图 N.3.1 DAG的介绍 1)在Spark里每一个操作生成一个RDD,RDD之间连一条边,最后这些RDD和他们之间的边组成一个有向无环图,这个就是DAG。而根据RDD之间依赖关系的DAG划分成不同的Stage(调度阶段),一个Stage就是一个job任务。而依赖有2个作用:用来解决数据容错的高效性;其二用来划分stage。 N.3.2 RDD的依赖关系 1)RDD和它依赖的父RDD(即 可以认为是通过运算产生出新RDD)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。 (1)窄依赖指的是子RDD的Partition会依赖父RDD的一个Partition,如下图左边部分举例的3中情况; (2)宽依赖指的是子RDD的Partition会依赖父RDD的不同Partition,如下图右边部分举例的2中情况; ————————————————————————
———————————————————————— N.3.3 划分stage 1)宽依赖是划分Stage的依据,遇到宽依赖就划分一个Stage。 2)A除就是一个宽依赖,F处就是一个宽依赖,然后一个总的依赖。 而在这个过程中Spark根据RDD之间依赖关系的DAG划分成不同的Stage(调度阶段),一个Stage 就写到一个job任务。Stage就是前后的算子合在一起作为一个整体的算子阶段。 ————————————————————————
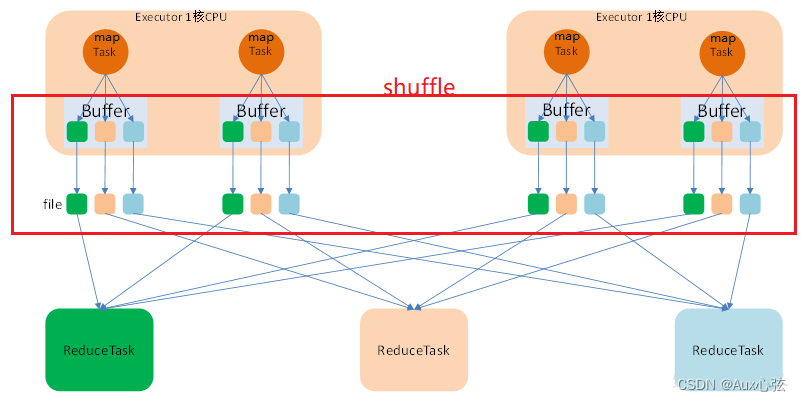
———————————————————————— N.3.4 Hashshuffle 1)当使⽤reduceByKey、groupByKey、sortByKey、countByKey、join、cogroup, repartition等操作的时候,会发⽣shuffle操作。 2)在map阶段,除了map的业务逻辑外,还有shuffle write的过程,这个过程涉及序列化、磁盘IO等耗时操作;在reduce阶段,除了reduce的业务逻辑外,还有shuffle read过程,这个过程涉及到⽹络IO、反序列化等耗时操作。所以整个shuffle过程是极其昂贵的。 ————————————————————————
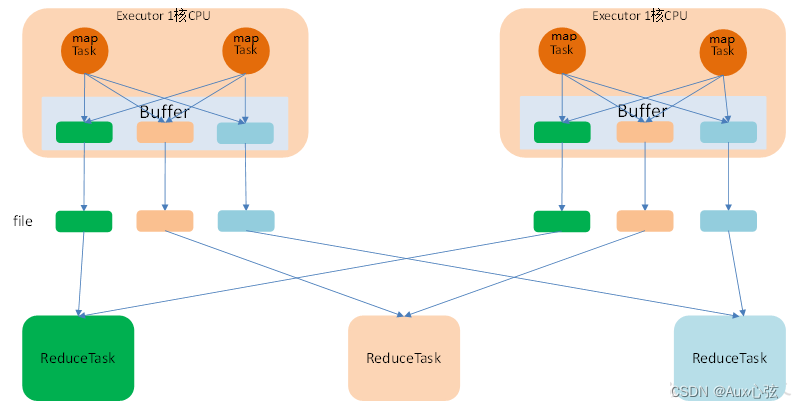
———————————————————————— 3)优化后的Hashshuffle : ————————————————————————
———————————————————————— N.2 分区数和分区方式 N.2.1 分区数和并行关系 1)默认分区数目如下 (0)在spark分区其实和flink类似 [1] spark在默认的情况下默认分区数据等于最小并发默认数据 sc.defaultMinPartitions = min(spark.default.parallelism,2) ,当然并发的默认数是可以改的。 [2] 所以如果你设置分区的话,那么你设置的并发数就会等于分区数。注意分区号是从零开始的。 此外分区数据可以通过 repartition和makeRDD是是设置分区操作,分区相当于最后输出了几个文件。 (1)Local模式: 默认为本地机器的CPU数目,若设置了loca[N],则默认为N。 (2)Standalone或者Yarn模式: 在“集群中所有CPU核数总和”和“2”这两者中取较大值作为默认值。 (3)详细的分区数情况 [1] 通过textFile方式生成的rdd则默认的分区数是: al rdd = sc.textFile(“path/file”) 情况一:rdd的分区数 = max(本地file的分片数, sc.defaultMinPartitions) 情况二:rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions) [2] 从HBase的数据表转换为RDD,则该RDD的分区数为该Table的region数 [3] 基于direct直连方式读取kafka数据 Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。 所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。 N.2.2 分区方式 (1)哈希分区(HashPartitioner)和范围分区(RangePartitioner)。 其中,哈希分区是根据哈希值进行分区; 范围分区是将一定范围的数据映射到一个分区中。 这两种分区方式已经可以满足大多数应用场景的需求。 与此同时,Spark也支持自定义分区方式,即通过一个自定义的Partitioner对象来控制RDD的分区,从而进一步减少通信开销。 |




【本文地址】
今日新闻 |
推荐新闻 |